Spark
SparkCore
Spark工作流程
图解:
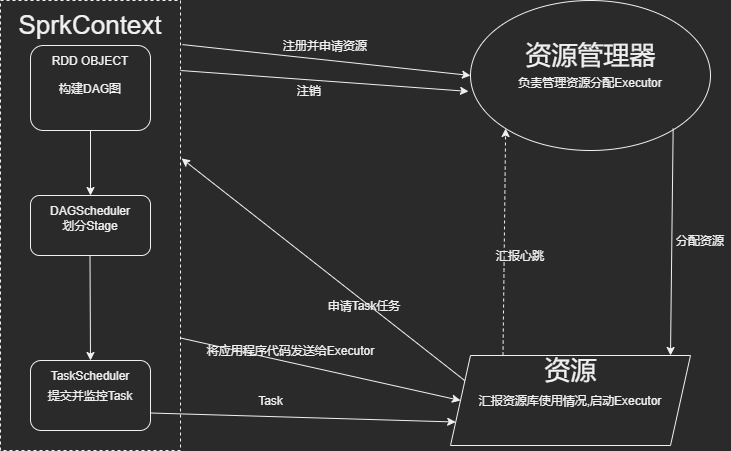
文字解说:
1.SparkContext向资源管理器注册并申请资源运行Executor
2.资源管理器分配资源,运行Executor
3.Executor发送心跳至资源管理器
4.SparkContext构建DAG
5.根据宽表划分Stage
6.将Stage发送给TaskScheduler
7.Executor向SparkContext请求Task
8.TaskScheduler将Task给Executor执行.同时SparkContext将应用程序代码发送给Executor
9.Task在Executor上运行,运行完毕,释放资源.
Spark的组件构成:
- Master 管理集群与节点,不参与计算
- Work 计算节点,进程本身不参与计算
- Driver 运行程序的main()方法,创建SparkContext
- SparkContext 管理Application的整个生命周期,包括DAGScheduler等组件
- Client 用户提交程序的入口
Spark组件中RDD的机制理解
- RDD(Resilient Distributed Dataset)是弹性分布式数据集
- 但是,它本身是不存储数据的:
- 初代RDD: 存储有分区信息和得到数据的方法.
- 子代RDD: 存储血缘关系.
- 那么数据在哪里呢?在Task里面.
- 所以每一次执行collect或者行动算子都要重塑一遍血缘关系.
补充:
- 一下有一组关于RDD的定义(据说是Spark源码中对于RDD的定义)
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDS
- Optionally,a partitioner for key-value RDDS
- Optionally,a list of preferred locations to compute each split on(e.g. block locations for an HDFS file)



