UDF
package com.tzk.sparksql.udf
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object UDF_ {
def main(args: Array[String]): Unit = {
//配置环境
val conf = new SparkConf().setMaster("local[*]").setAppName("udf")
val spark = SparkSession.builder().config(conf).getOrCreate()
val sc = spark.sparkContext
//操作
val df = spark.read.json("datas/1.json")
spark.udf.register("addName","Name:"+_)
df.createOrReplaceTempView("user")
spark.sql("select addName(name) as name,* from user").show
//关闭环境
spark.stop()
}
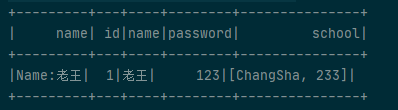
}运行效果图
UDAF
现在统一使用Aggregator强类型
推荐使用方法如下
package com.tzk.sparksql.test01
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Encoder, Encoders, Row, SparkSession, TypedColumn, functions, types}
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
object Demo01 {
def main(args: Array[String]): Unit = {
//创建sql环境
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLTest")
val sparkSeesion = SparkSession.builder().config(conf).getOrCreate()
//操作
import sparkSeesion.implicits._
val df = sparkSeesion.read.json("datas/1.json")
df.show
//现在推荐使用方法
df.createOrReplaceTempView("user")
sparkSeesion.udf.register("avgPassword",functions.udaf(new MyAvfUDAF()))
sparkSeesion.sql("select avgPassword(password) from user").show
//早期使用强类型的方法如下
val ds = df.as[User]
val column: TypedColumn[User, Long] = (new MyAvgPassword).toColumn
ds.select(column).show()
//关闭sql环境
sparkSeesion.close()
}
}
case class User(id:String,name:String,password:Long,school:(String,String))
case class Buff(var total:Long,var count:Long)
class MyAvfUDAF extends Aggregator[Long,Buff,Long]{
override def zero: Buff = {
Buff(0L,0L)
}
override def reduce(b: Buff, a: Long): Buff = {
b.total += a
b.count += 1
b
}
override def merge(b1: Buff, b2: Buff): Buff = {
b1.total += b2.total
b1.count += b2.count
b1
}
override def finish(reduction: Buff): Long = {
reduction.total/reduction.count
}
override def bufferEncoder: Encoder[Buff] = Encoders.product
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
class MyAvgPassword extends Aggregator[User,Buff,Long]{
override def zero: Buff = Buff(0L,0L)
override def reduce(b: Buff, a: User): Buff = {
b.total += a.password
b.count += 1
b
}
override def merge(b1: Buff, b2: Buff): Buff = {
b1.total += b2.total
b1.count += b2.count
b1
}
override def finish(reduction: Buff): Long = {
reduction.total/reduction.count
}
override def bufferEncoder: Encoder[Buff] = Encoders.product
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
//过时的肉类型使用法
/*class MyAvgUDAF extends UserDefinedAggregateFunction{
override def inputSchema: StructType = {
StructType(
Array(
StructField("age",LongType)
)
)
}
override def bufferSchema: StructType = {
StructType(
Array(
StructField("total",LongType),
StructField("count",LongType)
)
)
}
override def dataType: DataType = LongType
override def deterministic: Boolean = true
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0,buffer.getLong(0)+input.getLong(0))
buffer.update(1,buffer.getLong(1)+1)
}
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0,buffer1.getLong(0)+buffer2.getLong(0))
buffer1.update(1,buffer1.getLong(1)+buffer2.getLong(1))
}
override def evaluate(buffer: Row): Any = {
buffer.getLong(0)/buffer.getLong(1)
}
}*/


