DataFrame
他是一种以RDD为基础的分布式数据集,相当于传统数据库的二维表.
但是,他与RDD的主要区别在于,他包含了schema元信息.
即他为数据提供了schema的视图.具体见下图
![RDD[person]](/2022/04/14/sparksql-zu-jian-li-jie/RDDPerson.png)
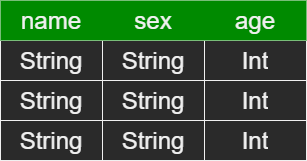
然后有以下几点需要理解:
- 他是包含schema元数据信息的
- 这使得spark-sql可以了解到数据更多的结构信息.
- 这就意味着,sqarkSQL可以针对藏于DataFrame背后的数据源以及作用于其上的变化做出针对性的优化,这样也就理所当然的相较于RDD,其的效率得到大幅度的提升.(SparkCore只能作用于stage层面的流水线优化)
- 这使得spark-sql可以了解到数据更多的结构信息.
- 也是懒执行的,但是性能上要比RDD高
- 这主要得益于他的优化执行计划,即查询计划通过Spark catalyst optimiser进行优化.(具体理解,看下前面代码和解析)
如果按照这个代码逻辑执行,那么,在fitler之前就行join操作,必然是没有在fitler进行join操作来得效率高的.因为join是要进行shuffle的,越是大量的数据说要进行的shuffle代价就越是庞大.所以Spark SQL的查询优化器会将fitler放在join之前进行操作.users.join(evnets,users("id") === events("uid")) .filter(events("data") > "2015-01-01")
- 这主要得益于他的优化执行计划,即查询计划通过Spark catalyst optimiser进行优化.(具体理解,看下前面代码和解析)
DataSet
他是spark 1.6添加的新抽象.
- DataSet = RDD的强类型优势(强大的lambda函数能力) + Spark SQL 的优化执行(DataFrame的优势)
- DataSet 如何使用类型:DataSet[Person],DataSet[Student]
- DataFrame相当于是DataSet的一个特例,类型为RowDataFrame = DataSet[Row]
- DataSet 也可以使用功能性的转换(操作 map,flatMap,filter
等等)



