hadoop中 hdfs,yarn..等等流程图
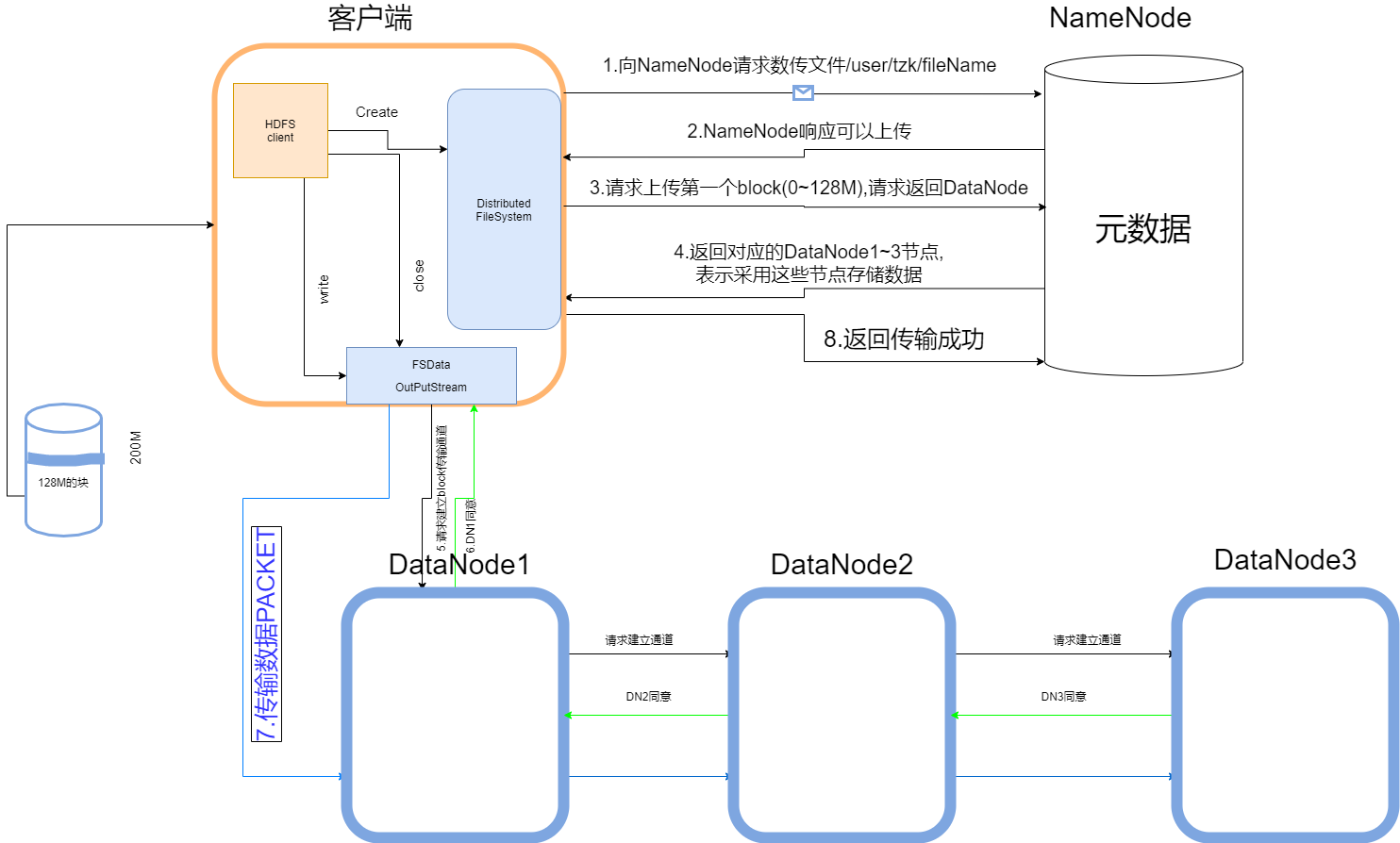
HDFS写流程图:
文字解说:
HDFS客户端创建分布式文件系统:
- 1.向NameNode提交在HDFS上创建文件的申请.
- DataNode核对:
是否拥有权限(是)
是否才在此文件(否) - 2.满足条件后,NameNode返回同意响应.
- 3.向NameNode提交上传第一个块的请求
- 4.NameNode返回用于存储该块的DataNode
- 选取策略:
本地节点
其他机架上的节点
其他机架上的不通节点
收到消息后,HDFS客户端打开outputstream:
- 5.向DataNode1提交请求,建立Block传输通道,DataNode之间层层传递直到最后一个DataNode3.
- 6.DataNode3返回同意,在层层同意之后返回FSDataOutputStream
- 7.然后开始以Packet(64k)为单位传递给DataNode
- 1.DataNode内部,数据是在ByteBuffer里不断流动给下一个DataNode的,与此同时,又会持久化于本地磁盘.
- 2.Packet每次传递后,节点都会逐层给与应答,只有当都成功了后,才会给与下一个Packet,否则再次传递.
- 3.Packet是由(chunk512byte+chunksum4byte(校验位))攒够64K形成的.
提一下,在HDFS客户端开启FSDataOutputstra之前,会先创建一个这个缓冲队列,这个队列就是用来慢慢形成一个个的Packet. - 传递完成后给与NameNode反馈