电商数据仓库项目
基准测试
为什么要做基准测试?
在企业中非常关心每天从Java后台拉取过来的数据,需要多久能上传到集群?消费者关心多久能从HDFS上拉取需要的数据?
为了搞清楚HDFS的读写性能,生产环境上非常需要对集群进行压测。
怎么做
- 第一步,设置统一网络传输速度 * hadoop102、hadoop103、hadoop104虚拟机网络都设置为100mbps。
原因:HDFS的读写性能主要受网络和磁盘影响比较大。
edit: 100Mbps单位是bit;10M/s单位是byte ; 1byte=8bit,100Mbps/8=12.5M/s。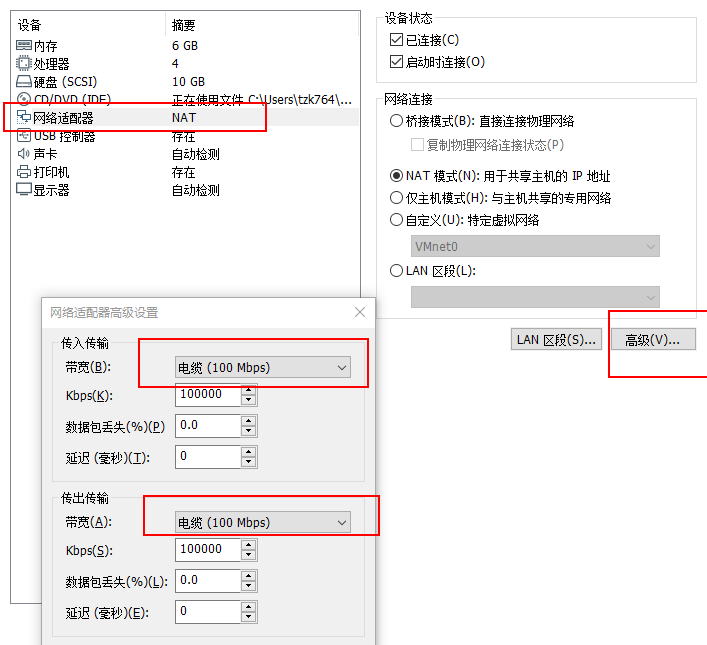 * 开启python的简单http服务器进行网速测试
* 开启python的简单http服务器进行网速测试
* 验证结果[tzk@hadoop101 module]$ python -m SimpleHTTPServer Serving HTTP on 0.0.0.0 port 8000 ... 192.168.32.1 - - [07/Oct/2021 19:42:38] "GET / HTTP/1.1" 200 - 192.168.32.1 - - [07/Oct/2021 19:42:38] code 404, message File not found 192.168.32.1 - - [07/Oct/2021 19:42:38] "GET /favicon.ico HTTP/1.1" 404 - 192.168.32.1 - - [07/Oct/2021 19:42:43] "GET /bigtable.lzo HTTP/1.1" 200 -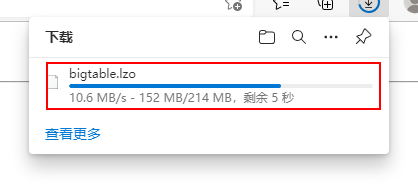
- 第二步,测试hdfs的写性能
向HDFS写10个128M的文件[tzk@hadoop101 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB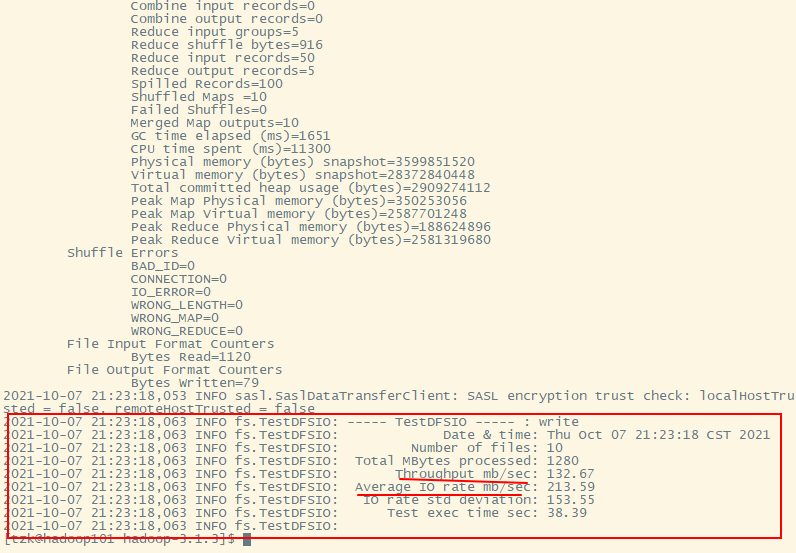
两个平均数:- 第一个的计算方式: 所有数据量相加 / 总时间
- 第二个的计算方式: 每一个map的平均速度相加
由上图可以看出,这两个平均速度远远大于网络速度.很明显,这里走的是磁盘,并没有走网络.
即:只在hadoop101上运行,因为我们在一开始把备份数改成了1.现在去hdfs-site.xml进行修改为3
来看一下运行结果图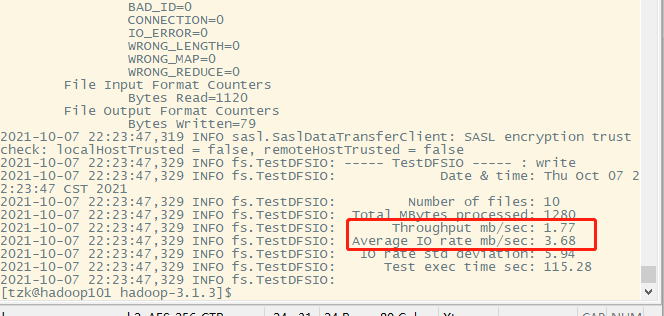
10个任务,由于我们的客户端是在hadoop101上,所以网络传输为 10*20分.
那么传输速度为:
v X 20
实测数据: 1.77 * 20 = 35.4
每台服务器速度(按最大值:100 / 8 = 12.5)相加: 12.5 + 12.5 + 12.5 = 37.5
由此可得,带宽已经跑满了
- 第三步,测试HDFS的读性能
客户端: hadoop101[tzk@hadoop101 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB - 测试结果图:*

最后,删除测试生成数据
[tzk@hadoop101 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean使用Sort程序评测MapReduce
(1)使用RandomWriter来产生随机数,每个节点运行10个Map任务,每个Map产生大约1G大小的二进制随机数
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data(2)执行Sort程序
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data(3)验证数据是否真正排好序了
[atguigu@hadoop102 mapreduce]$
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-datahadoop参数调优
1 )HDFS参数调优
hdfs-site.xml
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>计算公式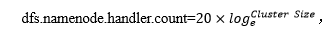
通过python实现计算
[tzk@hadoop101 hadoop-3.1.3]$ python
Python 2.7.5 (default, Apr 2 2020, 13:16:51)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(3))
21
>>> quit()2 )YARN参数调优
yarn-site.xml
(1)情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
(2)解决办法:
NodeManager内存和服务器实际内存配置尽量接近,如服务器有128g内存,但是NodeManager默认内存8G,不修改该参数最多只能用8G内存。NodeManager使用的CPU核数和服务器CPU核数尽量接近。
①yarn.nodemanager.resource.memory-mb NodeManager使用内存数
②yarn.nodemanager.resource.cpu-vcores NodeManager使用CPU核数
kafka压测
生产压测
kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka --create --replication-factor 2 --partitions 3 --topic test
#再来一遍
kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka --create --replication-factor 2 partitions 3 --topic test
#在来亿遍
kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka --create --replication-factor 2 --partitions 3 --topic test
#生产测试
kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 10000000 --throughput -1 --producer-props bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092
kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 10000000 --throughput -1 --producer-props bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092测试结果图:
集群总带宽: 12.5 + 12.5 + 12.5 约等于 10 + 10 + 10 = 30M/s
由于有两个副本,则传输速度应该为: 30 / 2 = 15M/s
测试结果与预期相符
消费压测
kafka-consumer-perf-test.sh --broker-list hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1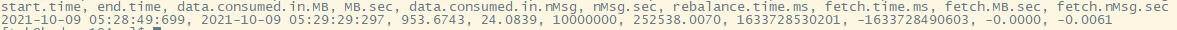
将 fetch-size的值加大10倍
# threads 地址对结果没影响,因为底层源码中并没有调取它
kafka-consumer-perf-test.sh --broker-list hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic test --fetch-size 100000 --messages 10000000 --threads 1


